참고문헌
https://docs.spring.io/spring-batch/docs/current/reference/html/job.html#configuringJobRepository
Configuring and Running a Job
Because the script launching the job must kick off a Java Virtual Machine, there needs to be a class with a main method to act as the primary entry point. Spring Batch provides an implementation that serves just this purpose: CommandLineJobRunner. It’s i
docs.spring.io
1. JobRepository란?
스프링 배치는 잡이 실행될 때 잡의 상태를 JobRepository에 저장해 관리한다.
a. 관계형 데이터베이스 사용
https://docs.spring.io/spring-batch/docs/3.0.x/reference/html/metaDataSchema.html
Appendix B. Meta-Data Schema
The Spring Batch Meta-Data tables very closely match the Domain objects that represent them in Java. For example, JobInstance, JobExecution, JobParameters, and StepExecution map to BATCH_JOB_INSTANCE, BATCH_JOB_EXECUTION, BATCH_JOB_EXECUTION_PARAMS, and BA
docs.spring.io
https://jojoldu.tistory.com/326?category=902551
3. Spring Batch 가이드 - 메타테이블엿보기
이번 시간에는 Spring Batch의 메타 테이블에 대해 좀 더 자세히 살펴보겠습니다. 작업한 모든 코드는 Github에 있으니 참고하시면 됩니다. 지난 시간에 Spring Batch의 메타 테이블을 살짝 보여드렸는데
jojoldu.tistory.com
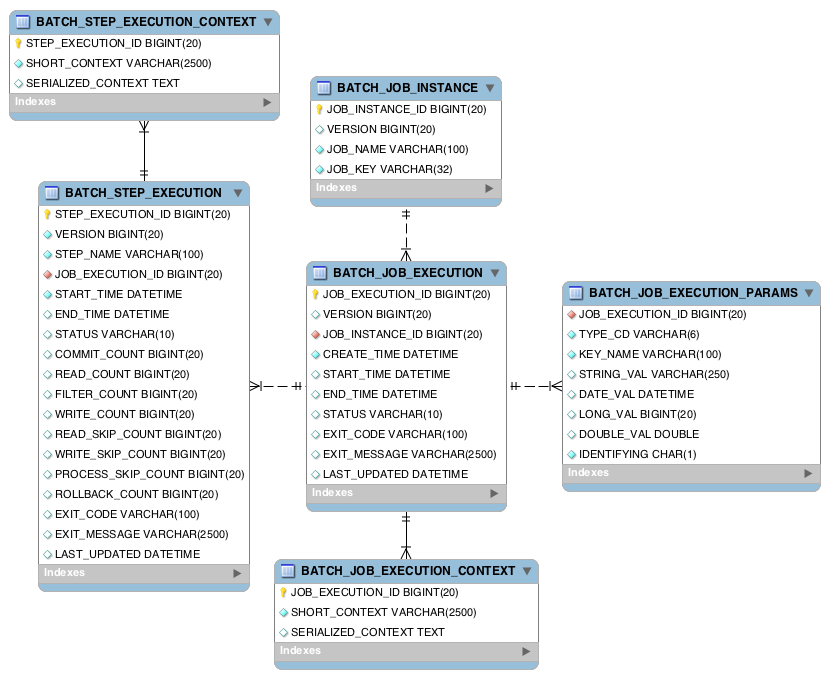
BATCH_JOB_INSTANCE: 잡의 논리적 실행BATCH_JOB_EXECUTION: 배치 잡의 실제 실행 기록- 잡이 실행될 때마다 새 레코드가 해당테이블에 생성되고, 잡 진행중 주기적으로 업데이트
BATCH_JOB_EXECUTION_PARAMS: 잡이 매번 실행될 때마다 사용된 잡 파라미터를 저장- 잡에 전달된 모든 파라미터가 테이블에 저장된다. 재시작시에는 잡의 식별정보 파라미터만 자동으로 전달
BATCH_JOB_EXECUTION_CONTEXT: JobExecution의 ExecutionContext를 저장하는 곳일반적으로 "중단된 위치에서 시작"할 수있게해준다.- 해당 테이블에서 탐색 후 동일한 JobParameter로 성공한 기록이 있을 때만 재수행이 안된다.
BATCH_STEP_EXECUTION: 스텝의 시작, 완료, 상태에 대한 메타데이터를 저장읽기(read), 처리(process), 쓰기(write), 건너뛰기(skip) 횟수와 같은 모든 데이터가 저장된다.- 스텝 분석이 가능하도록 다양한 횟수 값을 추가로 저장한다
BATCH_STEP_EXECUTION_CONTEXT: 스텝수준에서 컴포넌트의 상태를 저장하는 데 사용
메타 이용시 권장하는 인덱싱

b. 인메모리 JobRepository
인프라 구성작업에서의 비용을 생각해서, 스프링 배치는 java.util.Map 객체를 데이터 저장소로 사용하는 JobRepository 구현체를 제공한다.
MapJobRepositoryFactoryBean : deprecated
2. 배치 인프라스트럭처 구성하기
@EnableBatchProcessing 애너테이션 => JobRepository를 사용할 수 있다.
BatchConfigurer 인터페이스
스프링 배치 인프라스트럭처 컴포넌트의 구성을 커스터마이징하는 데 사용되는 전략 인터페이스(strategy interface)
애너테이션 적용시 빈 추가 과정
- BatchConfigurer 구현체에서 빈 생성
- SimpleBatchConfiguration에서 스프링의 ApplicationContext에 생성한 빈 등록
public interface BatchConfigurer {
JobRepository getJobRepository() throws Exception;
PlatformTransactionManager getTransactionManager() throws Exception;
JobLauncher getJobLauncher() throws Exception;
JobExplorer getJobExplorer() throws Exception;
}a. JobRepository 커스터마이징
JobRepository는 JobRepositoryFactoryBean이라는 팩토리빈을 통해 생성된다.
재정의해야하는 일반적인 시나리오 : ApplicationContext에 두 개 이상의 데이터 소스가 존재하는 경우
DefaultBatchConfigurer를 상속해 인터페이스의 모든 메서드를 다시 구현하지 않아도 된다.
b. TransactionManager 커스터마이징
PlatformTransactionManager : 프레임워크가 제공하는 모든 트랜잭션 관리 시에 스프링 배치가 사용하는 컴포넌트
트랜잭션을 프레임워크의 핵심 컴포넌트로 취급하고있다.
c. JobExplorer 커스터마이징
JobExplorer : JobRepository의 데이터를 읽기 전용으로 볼 수 있는 기능을 제공
JogRepository : 배치 잡의 상태를 저장하는 데이터 저장소에 데이터를 저장하고 조회할 수 있도록 API 제공
JobRepository와 JobExploer는 동일한 데이터 저장소를 사용하므로 둘 중 하나만 커스터마이징하기 보다는 동기화되도록 둘 다 커스터마이징 하는 것이 좋다.
d. JobLauncher 커스터마이징
스프링 부트는 기본적으로 스프링 배치가 제공하는 SimpleJobLauncher를 사용 >. 스프링 부트의 기본 메커니즘으로 잡을 실행할 때는 대부분 JobLauncher를 커스터마이징 할 필요가 없다.
데이터베이스 구성하기
스프링 부트를 사용할 때는 데이터베이스 드라이버를 클래스 경로에 추가하고 적절한 프로퍼티를 구성한다.
spring:
datasource:
driveClassName: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/spring_batch
username: 'root'
password: 'myPassword'
batch:
initialize-schema: alwaysspring.batch.initialize-schema
- always : 애플리케이션을 실행할 때마다 스크립트가 실행
- never : 스크립트를 실행하지 않음
- embedded : 내장 데이터베이스를 사용할 때, 각 실행 시마다 데이터가 초기화된 데이터베이스 인스턴스를 사용한다는 가정으로 스크립트를 실행
3. 잡 메타데이터 사용하기
JobExplorer 인터페이스 : 데이터베이스에 직접 접근한다 > JobInstance 및 JobExecution과 관련된 정보를 얻을 수 있는 메서드를 제공한다.
'Reading Record > 스프링 배치 완벽 가이드' 카테고리의 다른 글
| 7장 ItemReader: Json 까지 (0) | 2021.11.22 |
|---|---|
| 6장 잡 실행하기 (0) | 2021.11.15 |
| 4장 잡과 스텝 이해하기 : 스텝 알아보기 (0) | 2021.10.24 |
| 4장 잡과 스텝 이해하기 : ExecutionContext 까지 (0) | 2021.10.17 |
| 13장 배치 처리 테스트하기 (0) | 2021.10.12 |


