Java에서 대량의 데이터를 DB에 삽입할때 JDBC Batch를 활용하면 성능이 대폭 향상됩니다.
정산과 같은 실시간 처리가 필요없고, 대량의 데이터를 다루는 배치성 작업은 위 기능을 활용하면 효율적인 처리가 가능한데요,
아쉽게도 JPA를 사용하는 경우 JDBC Batch 기능을 사용하는데 제약이 많습니다.
이번 글에서는 JPA 환경에서 삽입 성능을 향상할 수 있는 방법을 공유하겠습니다.
JDBC Batch 란?
JDBC는 Java에서 db를 다루기 위한 API 스펙으로 각 벤더사가 JDBC 스펙을 구현한 드라이버를 제공합니다.
JDBC 스펙에는 대량의 데이터 처리를 위한 Batch Api를 제공하고 있고, 대량의 데이터 처리 시에는 꼭 해당 API를 활용해 효율적으로 처리해야합니다.
아래 코드는 JDBC Batch Api를 활용하는 코드입니다.
try (Connection connection = dataSource.getConnection()) {
final String sql = "insert into pay(ID, service, pay_amount) values (?, ?, ?)";
try (PreparedStatement preparedStatement = connection.prepareStatement(sql)) {
for (Pay pay : Pays) {
preparedStatement.setLong(1, pay.id);
preparedStatement.setLong(2, pay.service);
preparedStatement.setLong(3, pay.amount);
preparedStatement.addBatch();
}
preparedStatement.executeBatch();
}
}결제 데이터 리스트를 돌면서 addBatch를 호출해 하나의 청크로 묶고 마지막에 executeBatch를 호출해 하나의 쿼리로 묶어 한번에 삽입합니다.
하나의 청크로 묶인 쿼리는 아래와 같이 하나의 insert 문으로 DB에서 실행됩니다.
//batch처리가 안된 query
insert into pay (id, service, pay_amount) values (1,'BAEMIN', 1000);
insert into pay (id, service, pay_amount) values (2,'BMART',3000);...
//batch처리가 된 query
insert into pay (id, service, pay_amount)
values (1,'BAEMIN', 1000),(2,'BMART',3000) .....;- 묶어서 처리하는 쿼리는 삽입 쿼리를 하나씩 받아서 처리할때보다 훨씬 빠르게 실행됩니다.
* JDBC Batch 옵션
JDBC Batch API를 사용한다고 바로 쿼리가 묶이는건 아닙니다.
Batch Api를 활용하기 위해선 Mysql JDBC 드라이버에서 제공하는 옵션 중 하나인 rewriteBatchedStatements 옵션을 설정해야 합니다.
rewriteBatchedSteatements 옵션은 JDBC에서 사용하는 batch 쿼리를 재작성하여 성능을 향상시키는 옵션입니다.
해당 옵션을 활성화 하지 않으면 Batch Api를 호출해도 쿼리를 묶어서 실행하지 않으니 주의해야합니다.
왜 JPA에서 Batch Insert가 안되는가?
JPA와 Mysql을 활용할때 가장 많이 사용하는 ID 생성 방식은 AUTO_INCREMENT를 활용한 IDENTITY 전략입니다.
MySQL에서 AUTO_INCREMENT를 사용하면, INSERT 문에서 자동 생성된 ID 값을 얻기 위해 추가적인 SQL 쿼리를 실행해야 합니다.이는 JDBC의 Batch 처리 기능을 사용할 때 문제가 될 수 있습니다.
AUTO_INCREMENT는 INSERT 쿼리를 실행한 후에 ID 값을 얻을 수 있는데,
이 부분이 하이버네이트의 Transactional write behind(트랜잭션을 지원하는 쓰기 지연: 트랜잭션이 커밋 될때까지 쿼리를 모아뒀다가 한번에 실행하는 방식)과 충돌이 발생해 batch 처리가 제대로 이루어지지 않을 수 있습니다.
따라서 IDENTITY전략을 사용하면, rewriteBatchedStatements 옵션을 사용해도 batch 처리의 성능 향상 효과를 기대하기 어렵습니다.
그래서 Batch기능을 활용하고 싶다면 IDENTITY전략이 아닌 다른 ID 할당 전략을 채택해야합니다.
* JPA ID 생성 전략
Hibernate에서 지원하는 ID 생성 전략에는 총 4가지가 있습니다.
- 직접 할당: ID를 어플리케이션에서 직접 할당
- IDENTITY: ID 생성을 데이터베이스에서 생성 후 할당
- SEQUENCE: 데이터베이스의 시퀀스 오브젝트를 사용하여 할당
- TABLE: ID 관리하는 테이블을 만들어 할당
@Entity
@Table
class Pay(
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id")
val id: Long? = null,
@Column(name = "service")
val service: String,
@Column(name = "pay_amount")
val payAmount: Long,
)- Mysql에서 AUTO_INCREMENT를 선택할 경우 ID 할당 전략을 IDENTITY로 선택하게 되는데, 해당 전략을 쓸 경우에는 Batch Insert를 지원하지 않습니다.
JPA에서 Batch를 사용하려면..
지금까지 JDBC Batch에 대한 개념과 JPA에서 Batch가 안되는 경우를 알아봤는데요,
이제 JPA에서 Batch API를 활용하기 위한 방법을 알아보겠습니다.
아래 코드는 Batch Insert 테스트 예제 코드입니다.
pay(결제)를 incomeFee(입금수수료)를 계산해 저장하는 단순한 배치입니다.
아래 코드에서 JpaCursorItemReader를 통해서 Pay를 JPA Entity 객체로 청크단위로 읽은 후 Processor를 통해 입금수수료를 계산해 IncomeFee라는 entity로 변환합니다.
변환된 Entity 객체를 청크단위로 삽입합니다.
@Configuration
class IncomeFeeJob(
private val jobBuilderFactory: JobBuilderFactory,
private val stepBuilderFactory: StepBuilderFactory,
private val entityManagerFactory: EntityManagerFactory,
) {
@Bean(name = [JOB_NAME])
fun job(): Job = jobBuilderFactory.get(JOB_NAME)
.start(step())
.preventRestart()
.build()
@JobScope
@Bean(STEP_NAME)
fun step(): Step {
return stepBuilderFactory.get(STEP_NAME)
.chunk<Pay, IncomeFee>(500)
.reader(reader())
.processor(processor())
.writer(writer())
.build()
}
@Bean("${STEP_NAME}Reader")
fun reader(): JpaCursorItemReader<Pay> {
return JpaCursorItemReaderBuilder<Pay>()
.name("JpaCursorItemReader")
.entityManagerFactory(entityManagerFactory)
.queryString("SELECT p FROM Pay p")
.build()
}
@StepScope
@Bean("${STEP_NAME}Processor")
fun processor(): ItemProcessor<Pay, IncomeFee> {
return ItemProcessor { pay ->
IncomeFee(
payID = pay.ID!!,
incomeAmount = pay.payAmount / 2,
)
}
}
@StepScope
@Bean("${STEP_NAME}Writer")
fun writer(): JpaItemPersistWriter<IncomeFee> {
return JpaItemPersistWriter(entityManagerFactory)
}
companion object {
const val JOB_NAME = "IncomeFeeJob"
const val STEP_NAME = "${JOB_NAME}Step"
}
}이 배치 작업에서 JDBC Batch가 제대로 동작하려면 Jpa 설정과 ID 전략을 바꿔야 합니다.
우선 JPA Batch 옵션을 살펴보겠습니다.
JPA Batch 옵션
대량 데이터 처리를 위해선 아래의 JPA 옵션을 꼭 확인한 후 적절하게 설정해야 합니다.
batch_size
이 옵션은 Hibernate가 데이터베이스에 대해 배치 처리를 수행할 때 한 번에 처리할 INSERT, UPDATE 또는 DELETE 문의 개수를 지정합니다.
order_inserts
Entity 개체를 데이터베이스에 삽입할 때 개체가 생성된 순서대로 SQL INSERT 문을 생성합니다. 이 때, 개체 간에 상호 참조 관계가 있으면 상위 개체부터 삽입되어야 하므로 삽입 순서가 중요합니다.
개체 삽입 시 쿼리의 실행 순서를 정렬하여 상위 개체를 먼저 삽입하도록 합니다. 이를 통해 개체 간 참조 관계를 고려하여 데이터베이스 쿼리의 실행 계획을 최적화하고, 성능을 향상시킬 수 있습니다.
하지만 이 옵션은 개체의 수가 많을수록 INSERT 문의 실행 계획을 최적화하기 위해 추가 오버헤드가 발생할 수 있습니다.
order_updates
이 옵션은 Hibernate가 UPDATE 문을 배치 처리할 때, 엔티티의 변경 순서를 보장하기 위해 엔티티를 변경한 순서대로 UPDATE 문을 실행할 것인지 여부를 지정합니다.
기본적으로 Hibernate는 엔티티를 변경한 순서와 상관없이, 가능한 한 효율적인 방법으로 UPDATE 문을 배치 처리합니다.
그러나 order_updates 옵션을 활성화하면 Hibernate는 엔티티를 변경한 순서대로 UPDATE 문을 실행합니다. 이를 통해 엔티티의 변경 순서를 보장할 수 있습니다.
spring:
jpa:
properties:
hibernate:
jdbc.batch_size: 1000
order_inserts: true
order_updates: true
datasource:
hikari:
data-source-properties:
rewriteBatchedStatements: true
...적당한 batch_size와 삽입/수정 순서에 대한 옵션 설정을 완료했다면, 이제 ID 생성 전략을 확인해보겠습니다.
JPA ID 설정
위에서 설명한 것처럼 IDENTITY 전략을 선택하는 경우에는 JPA Batch를 사용할 수 없습니다.
Batch 기능을 활용하기 위해선 IDENTITY 전략외에 다른 전략을 선택해야 하는데요, 이번 장에서는 두가지 방법을 소개하겠습니다.
1. TABLE 전략을 활용한 Batch Insert
Mysql을 사용할 경우 시퀀스 기능을 별도로 제공하지 않아 ID 할당 방식으로 SEQUENCE 전략을 사용할 수 없습니다.
그래서 Mysql에서 Sequence를 활용하고 싶다면 TABLE 전략을 사용해야 합니다.
TABLE 전략은 ID값을 관리하는 테이블을 만들어 데이터를 삽입할때마다 ID관리 테이블에서 ID를 추출해서 사용하는 전략으로 시퀀스 명과 시퀀스값을 필드로 구성해야합니다.
create table sequence (
sequence_name varchar(255) not null comment '시퀀스명' primary key,
next_val bigint not null comment '시퀀스값'
) comment '시퀀스 테이블';JPA가 데이터를 저장할때 sequence 테이블에서 next_val을 할당된 수량만큼 업데이트하고 해당 구간을 ID값으로 사용합니다.
@Entity
@Table
@TableGenerator(name = "INCOME_FEE_SEQUENCE", table = "sequence", allocationSize = 100)
class IncomeFee(
@Id
@GeneratedValue(strategy = GenerationType.TABLE, generator = "INCOME_FEE_SEQUENCE")
@Column(name = "id")
val id: Long? = null,
@Column(name = "pay_id")
val payId: Long,
@Column(name = "income_amount")
val incomeAmount: Long,
)테이블을 생성하고 JPA Entity를 위와같이 구성해주면 데이터 삽입시 자동으로 ID를 주입해줍니다.
여기서 유의할 점은 allocationSize로 시퀀스 테이블에서 한번에 발번받을 ID 수량입니다.
100으로 설정해 둔 사이즈는 처음 next_val이 0인 상태에서 Pay를 삽입한다면 next_val이 100으로 업데이트 되고 0~100까지의 시퀀스를 사용할 수 있습니다.
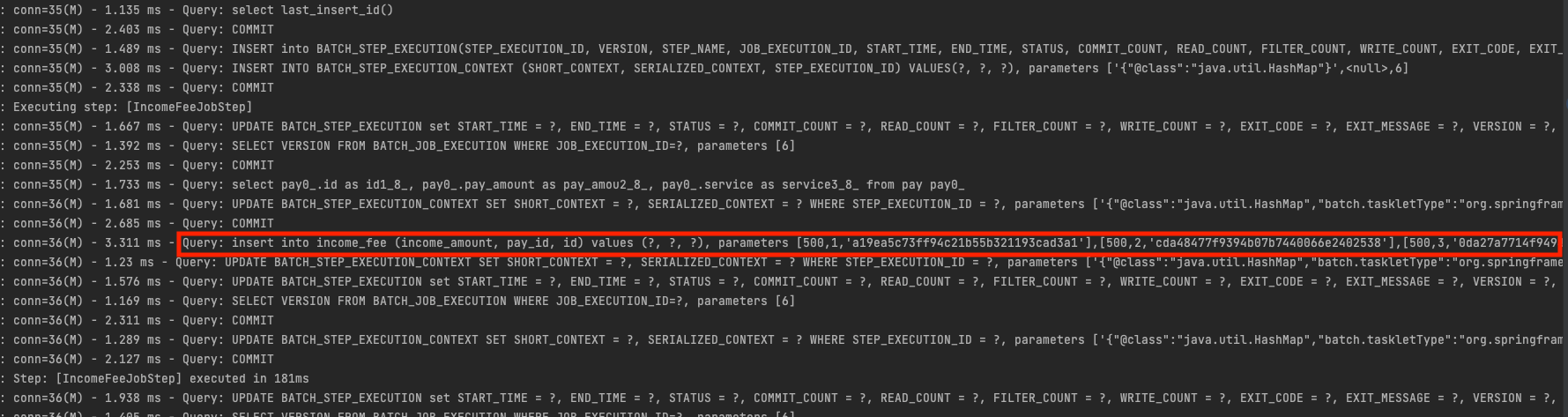
TABLE 전략을 구성한 후 예제 코드를 실행해보면 아래와 같이 삽입 쿼리가 묶여서 실행되는걸 확인할 수 있습니다.

테이블 전략을 사용하면 Batch 처리는 가능하지만 몇가지 단점이 있는데요,
우선 sequence 테이블에서 ID를 가져올때 해당 테이블에 잠금을 걸고 시퀀스를 가져옵니다.
때문에, 테이블이 잠겨 있을 때는 다른 트랜잭션이 해당 테이블에 시퀀스 로우에 접근하지 못해 성능 이슈가 발생할 수 있습니다.
또한 병렬 처리 환경에서는 여러 스레드가 동시에 ID 값을 생성하기 위해 테이블에 접근하므로 데드락 등의 문제가 발생할 수 있습니다.
이같은 단점으로 위 전략은 실시간 처리를 지원해야하는 도메인 보단 후속 배치 작업에만 사용하는 도메인에 적용하는 것이 좋습니다.
2. UUID PK를 활용한 Batch Insert
Table 전략을 사용하지 못하는 경우(실시간 처리와 배치처리를 동시에 지원해야하는 경우)에는 Entity의 ID의 값을 어플리케이션에서 생성해 주입하는 방법을 채택할 수 있습니다.
아래 코드는 영속화 하기전에 UUID로 ID를 세팅하는 Entity 코드입니다.
@Entity
class IncomeFee(
id:String? = null,
@Column(name = "pay_id")
val payId: Long,
@Column(name = "income_amount")
val incomeAmount: Long,
) {
@Id
@Column(name = "id")
var Id: String? = id
protected set
@PrePersist
fun prePersist() {
this.id = id ?: uuid()
}
}위 Entity 코드는 데이터를 삽입하기 전에 prePersist 함수를 호출해 어플리케이션 레벨에서 id를 UUID로 할당해 줍니다.
직접 삽입을 사용하면 데이터 삽입전에 ID 값을 알 수 있으므로 JPA 쓰기지연에 영향을 받지 않고 Batch Insert를 수행할 수 있습니다.
또한 UUID로 ID를 선택하면 중복될 확률이 굉장히 적으며, 생성 속도도 빠르기 때문에 시스템에 부담을 덜어줍니다.
최근 어플리케이션의 유지 보수성과 확장성을 위해 헥사고날 아키텍처를 사용하는 경우가 많은데, 이 경우 특정 데이터 스토리지에 종속되지 않기 위해 ID 값을 문자열로 선택하는 경우가 종종 있습니다.
문자열로 생성된 ID는 데이터 스토리지에 종속되지 않고 비지니스 레이어를 구성할 수 있을 뿐 아니라 Jpa Batch 기능도 활용할 수 있으므로 좋은 선택지가 될 수 있습니다.
다만 문자열로 생성된 ID는 데이터 테이블의 인덱스 크기가 매우 커져 데이터베이스의 성능에 영향을 미칠 수 있습니다.
또한 PK를 UUID로 설정하면 인덱스 정렬이 어렵습니다.
UUID는 무작위로 생성되기 때문에 검색시 정렬에 사용하기 어려운 이슈가 있으므로 필요한 요구사항을 잘 파악한 후 적용해야합니다.
'스터디 > 스프링' 카테고리의 다른 글
| Spring Scheduler Cluster 기능 추가해보기 (0) | 2022.08.23 |
|---|---|
| fetch join 과 pagination 을 같이 쓸 때 [HHH000104: firstResult/maxResults specified with collection fetch; applying in memory] (2) | 2020.10.21 |
| JPA 사용시 테스트 코드에서 @Transactional 주의하기 (8) | 2020.09.23 |
| Spring을 이용한 AWS Credentials 설정 (1) | 2020.07.13 |
| Spring Boot logback 설정하기 (0) | 2020.06.14 |



