https://github.com/Java-Bom/ReadingRecord/issues/152
[아이템 83] 짜릿한 단일검사(racy single-check) · Issue #152 · Java-Bom/ReadingRecord
p.445 모든 스레드가 필드의 값을 다시 계산해도 상관없고 필드의 타입이 long과 double을 제외한 다른 기본 타입이라면, 단일 검사의 필드 선언에서 volatile 한정자를 없애도 된다. 질문 : 왜 long과 dou
github.com
이펙티브 자바를 읽으면서 짜릿한 단일검사(racy single-check)에 대해 찾아보던 중, 알게된 내용이다.
동기화의 기능
자바의 쓰레드 프로그래밍을 해보았다면 synchronized 키워드를 몇번 접해볼 수 있을 것이다. 동기화에서 synchronized 를 이용해 한가지 자원을 동시에 접근할 때 thread safe하게 자원의 내용을 변경할 수 있어, 이 기능만 동기화의 기능이라고 보기 쉽다. 즉 synchronized 가 걸려있는 블록 혹은 메서드에서 한번에 한 쓰레드씩 수행하도록 한다.
그러나 사실 동기화의 기능은 총 2가지이다.
a. 배타적 실행
위에 말한 대로 한 쓰레드가 변경하는 중이라서, 상태가 일관되지 않는 (공유하는 자원의) 객체를 현재 사용중인 쓰레드만 접근이 가능하고, 다른 쓰레드가 보지 못하게 막는 용도를 말한다.
이때 락에 대한 개념이 나온다. 락을 건 메서드에서 객체의 상태를 확인하고 필요하면 수정하도록 작성했을 때, 한 쓰레드에서 해당 메서드를 사용하게 되면 객체에 락이 걸리게 되고, 해당 객체는 다른 쓰레드에서 동시에 접근이 불가능하다.
즉 배타적 실행은 객체를 하나의 일관된 상태에서 다른 일관된 상태로 변화시키는 것이다.
b. 쓰레드 사이의 안정적 통신
동기화에는 중요한 기능이 하나 더 있다.
동기화 없이는 한 스레드가 만든 변화를 다른 스레드에서 확인하지 못할 수 있다.
동기화덕분에 한 스레드에서 락의 보호하에 수행된 수정사항을 다른 쓰레드에서 최종 결과를 볼 수 있다.
자바 언어에서 long과 double을 제외한 변수를 읽고 쓰는 동작은 원자적이다. 여러 쓰레드가 primitive 타입의 변수를 동기화 없이 수정하더라도, 각 스레드에서는 정상적으로 그 값을 온전하게 (연산중간에 끼어들지 않고 온전히) 읽어온다
원자적 연산
위에서 읽고 쓰는 동작이 원자적이라 했는데, 원자적 연산은 중단이 불가능한 연산을 이야기한다
여러 자바의 연산은 바이트코드로 이루어져 있는데, 하나의 연산을 수행하기 위해 바이트코드가 수행될 때 중간에 다른 쓰레드가 끼어들어서 연산의 결과가 올바르지 않게 변한다면 해당 연산은 원자적 연산이 아니다.
원자적이지 않은 동작의 예시로는 a++(증가 연산자)이 있다. cleancode책의 동시성 부록에서는 아래와 같은 설명이 나온다
lastId값이 42였다고 가정하자. 다음은 getNextId 메서드의 바이트 코드다.
예를 들어 첫째 스레드가 ALOAD 0, DUP, GETFIELD lastId까지 실행한 후 중단 되었다고 가정하자.
둘째 스레드가 끼어들어 모든 명령을 실행했다. 즉, lastId를 하나 증가해 43을 얻어갔다.
이제 첫째 스레드가 중단했던 실행을 재개한다.
첫째 스레드가 GETFIELD lastId를 실행한 당시 lastId 값은 42였다. 그래서 피연산자 스택에도 42가 들어있었다. 여기에 1을 더해 43을 얻은 후 결과를 저장한다.
첫째 스레드가 반환하는 값 역시 43이다. 둘째 스레드가 증가한 값은 잃어 버린다.
둘째 쓰레드가 첫째 스레드를 중단한 후 다시 실행된 첫째 스레드가 둘째스레드의 작업을 덮어썼기 때문이다.

즉, 여기서의 문제는 연산을 수행할 때 JVM에서 사용하는 프레임, 지연변수, 피연산자 스택에 저장하는 과정에서 원자적 연산이 아닌경우, 연산 중간 과정이 덮어씌워져 올바르지 않은 값을 갖는다는 것이다.
좀더 쉽게는 두개의 쓰레드에서 ++ 연산을 했으니 +2가 되어야하는데, ++ 연산이 원자적이지 않아 +1만 되었다는 것이다.
원자적 데이터에서의 동기화
위의 원자성에 대한 이야기를 들으면 원자적 데이터를 읽고 쓸 때는 (할당 연산은 원자적이다) 동기화를 하지 않아도 괜찮다고 생각 할 수 있다. (중단이 불가능하기 때문에!)
하지만 원자적 데이터라도 동기화가 필요하다
Java언어에서 스레드가 (원자적 데이터 값을 가지더라도) 필드를 읽을 때 '수정이 완전히 반영된' 값을 얻는다고 보장하지 않는다.
즉 A 쓰레드에서 필드를 수정했더라도, B 쓰레드에서 수정된 필드를 반드시 볼 수 있는 것은 아니라는 것이다.
따라서 한 쓰레드에서 수정이된 필드값을 다른 쓰레드에서 '잘 읽기' 위해서라도 동기화의 안정적인 통신이 필요하다
이는 자바 메모리 모델 때문이다.
동기화의 관점에서의 자바의 메모리 모델
동기화를 하지 않으면 스레드가 변수를 읽어올 때 각 쓰레드가 변수를 cached한 영역에서 읽어오게 된다. 그래서 한 쓰레드로 인해 해당 변수가 값이 변화해도, 다른 쓰레드에서는 이전에 읽었던 cached된 변수의 값을 읽기 때문에 변경된 사항을 볼 수 없다.
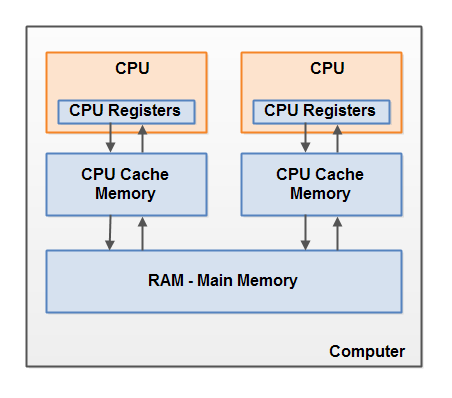
따라서 각 쓰레드에서 변경한 값을 값을 통신하기 위해 동기화가 필요하며. 이때 통신을 위한 동기화를 사용하기 위해서는 volatile 한정자를 사용하는 방법이 있다. (Synchronized는 배타적수행, 안정적 통신을 모두수행하는 것이고, volatile은 안정적 통신만을 수행한다고 생각하면 편하다)
즉, 여러 스레드가 공유하는 변수값을 읽어오기 위해서 volatile 키워드를 붙이면 그 변수를 읽어올때 각 쓰레드의 cached한 영역이 아닌 메인 메모리에서 직접 읽어오기 때문에 안정적인 통신을 보장할 수 있다.
https://github.com/Java-Bom/ReadingRecord/issues/142
[아이템 78] 동기화에서 통신과 자바메모리 모델의 관계 · Issue #142 · Java-Bom/ReadingRecord
p.415 이는 한 스레드가 만든 변화가 다른 스레드에게 언제 어떻게 보이는지를 규정한 자바의메모리 모델 때문이다 질문 : 자바의 메모리 모델과 상관관계가 궁금해. 여기에 링크 연결되어있는데
github.com
long과 double
위에서 "자바 언어에서 long과 double을 제외한 변수를 읽고 쓰는 동작은 원자적이다." 라고 언급했다. 그렇다면 long과 double은 왜 변수를 읽고 쓰는 동작이 원자적이지 않을까?
JVM 비트수와 관련이 있다. 자바 메모리 모델에 의하면 32비트 메모리에 값을 할당하는 연산은 중단이 불가능하다. (원자적이다)
그렇지만 long과 double의 경우에는 64비트의 메모리 공간을 갖고있기 때문이다.
https://docs.oracle.com/javase/specs/jls/se7/html/jls-17.html#jls-17.7
Chapter 17. Threads and Locks
class A { final int x; A() { x = 1; } int f() { return d(this,this); } int d(A a1, A a2) { int i = a1.x; g(a1); int j = a2.x; return j - i; } static void g(A a) { // uses reflection to change a.x to 2 } } In the d method, the compiler is allowed to reorder
docs.oracle.com
해당 글을 읽어보면, 3가지로 요약이 된다.
- volatile이 설정되지 않은 long, doulbe에 대한 쓰기는 두번에 이루어진다
=> 먼저 첫번째 32비트를 쓰고 다음 쓰기에서 두번째 32비트를 쓴다. - volatile이 설정된 long, double이라면 항상 원자적이다
- 프로그래머는 shared 되는 62bit 값은 volatile이나 synchronize 로 선언하는게 좋다. complication을 피하기 위해!
즉 첫 비트 32비트 값을 할당한 직후에, 즉 둘째 32비트를 할당하기 직전에 다른 쓰레드가 끼어들어 두 32비트 값중 하나를 변경할 수 있기 때문에 long, double은 원자적 연산이 될 수 없다.
하지만 volatile을 사용을 한다는 것은 여러 쓰레드에서 하나의 변수가 같은 값을 읽도록 보장하는 것이기 때문에, 메모리를 2번 접근을 하더라도 같은 값을 읽도록하는. 변수에 접근하는 연산을 원자적으로 수행하게 보장한다는 것이다.
in which case the Java memory model ensures that all threads see a consistent value for the variable
따라서 long, double 변수를 원자적으로 사용하고 싶다면 volatile로 선언하는게 좋다.
 |
김민정 - JavaBom | Backend 개발자 github : https://github.com/mjung1798 linkedin : https://www.linkedin.com/in/minjeong-kim-268796164/ blog : https://jyami.tistory.com/ |
'스터디 > 자바' 카테고리의 다른 글
| HikariCp 설정 유의사항 (0) | 2020.08.10 |
|---|---|
| Java의 Future Interface 란? (0) | 2020.07.14 |
| JMH 사용해보기 (1) | 2020.06.28 |
| 자바의 제네릭 (1) | 2020.06.14 |
| 자바 인액션으로 보는 병렬스트림 (0) | 2020.05.31 |



