ItemWriter
chunk 기반 처리방식이 도입되면서 아이템을 건건이 출력하지 않게됨.
그에따라 인터페이스도 ItemReader와 다르게 List를 파라미터로 받고있음.
public interface ItemWriter<T> {
/**
* Process the supplied data element. Will not be called with any null items
* in normal operation.
*
* @param items items to be written
* @throws Exception if there are errors. The framework will catch the
* exception and convert or rethrow it as appropriate.
*/
void write(List<? extends T> items) throws Exception;
}
ItemReader -> ItemProcessor 처리를 하나의 청크가 만들어 질 때까지 반복하고 청크가 만들어지면 ItemWriter로 전달하게됨. 따라서 쓰기 횟수가 청크 도입 이전보다 훨씬 적어졌음.
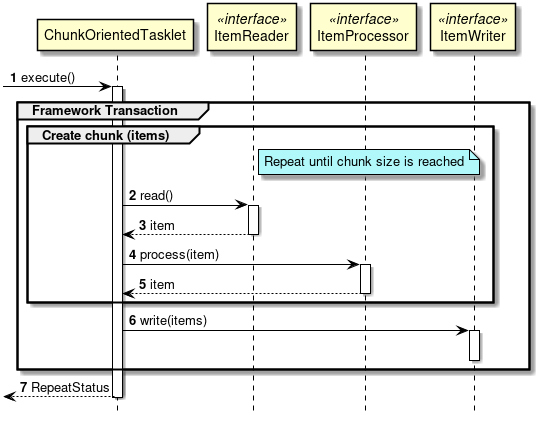
(출처: https://terasoluna-batch.github.io/guideline/5.0.0.RELEASE/en/Ch02_SpringBatchArchitecture.html)
파일 기반 ItemWriter
FlatFileItemWriter
텍스트 파일 출력을 만들 때 사용하는 스프링 배치의 ItemWriter 구현체
public class FlatFileItemWriter<T> extends AbstractFileItemWriter<T> {
protected LineAggregator<T> lineAggregator;
...
}LineAggregator 는 객체를 출력될 문자열로 변환하는 역할을 담당
일부 LineAggregator 구현체에서 사용되는 FieldExtractor 는 제공되는 아이템 객체의 필드에 접근할 수 있도록 하는 역할을 하며, getter 를 통해 프로퍼티에 접근하는 BeanWrapperFieldExtractor와 아이템을 바로 반환하는 PassThroughFieldExtractor 를 제공하고 있음

플랫파일에 한번 작성하게 되면 롤백을 할 수 없기 때문에 FlatFileItemWriter는 트랜잭션 주기 내에서 실제 쓰기작업을 최대한 지연시키도록 구현되어 있음. 쓰기 외 모든 처리 작업을 완료하고 실제로 디스크에 기록하기 직전에 PlatformTransactionManager가 트랜잭션을 커밋한다. 따라서 flatfile 쓰기 직전에 일어나는 실패에 대해서 디스크 작업 전에 롤백이 가능할 수 있도록 함.
예제
@Bean
@StepScope
public FlatFileItemWriter<Customer> customerItemWriter(@Value("#{jobParameters['outputFile']}") String outputFile) {
return new FlatFileItemWriterBuilder<Customer>()
.name("customerItemWriter")
.resource(new FileSystemResource(outputFile))
.formatted()
.format("%s %s lives at %s in %s, %s.") // text 포맷팅
.names(new String[] {"firstName", "lastName", "city", "state", "zipCode"}) // 순서대로
.build();
}
포맷팅 대신 구분자를 사용하려면 아래 설정만 바꿔주면됨
@Bean
@StepScope
public FlatFileItemWriter<Customer> customerItemWriterWithDelimiter(@Value("#{jobParameters['outputFile']}") String outputFile) {
return new FlatFileItemWriterBuilder<Customer>()
.name("customerItemWriterWithDelimiter")
.resource(new FileSystemResource(outputFile))
.delimited() // 구분자 설정
.delimiter(";") // ; 로 구분
.names(new String[] {"firstName", "lastName", "city", "state", "zipCode"})
.build();
}
output
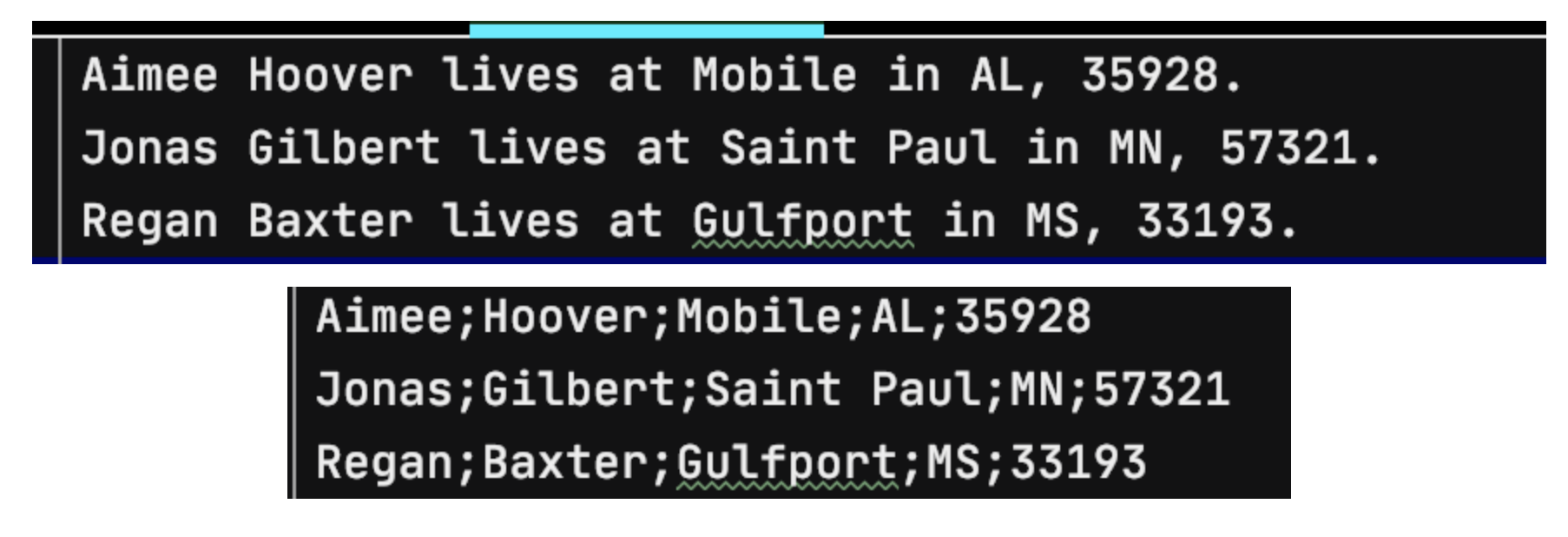
FlatFileItemWriterBuilder의 옵션
append 옵션은 여러 job에서 동일한 파일에 접근해야할 때 사용될 수 있음.
shouldDeleteIfEmpty는 헤더나 푸터가 작성되어도 아이템이 작성되지 않으면 파일이 삭제되고, shouldDeleteIfExist 이전 결과 파일을 보호하기 위해 사용될 수 있음.
.append(true) // 기존 파일이 있다면 추가할지의 여부. 기본값 false
.shouldDeleteIfEmpty(true) // 스탭 실행 이후에 아무 아이템도 작성되지 않았다면 파일이 삭제됨. 기본값 false
.shouldDeleteIfExists(false) // 같은 이름의 파일이 존재한다면 삭제하고 새 파일을 생성한다. 기본값 true. false일 경우 ItemStreamExceptionStaxEventItemWriter - Xml 출력
@Bean
@StepScope
public StaxEventItemWriter<Customer> xmlCustomerWriter(@Value("#{jobParameters['outputFile']}") String outputFile) throws Exception {
return new StaxEventItemWriterBuilder<Customer>()
.name("customerItemWriter")
.resource(new FileSystemResource(outputFile))
.marshaller(marshaller())
.rootTagName("customers")
.build();
}
private XStreamMarshaller marshaller() throws Exception {
Map<String, Class> aliases = new HashMap<>();
aliases.put("customer", Customer.class);
XStreamMarshaller marshaller = new XStreamMarshaller();
marshaller.setAliases(aliases);
marshaller.afterPropertiesSet();
return marshaller;
}
결과
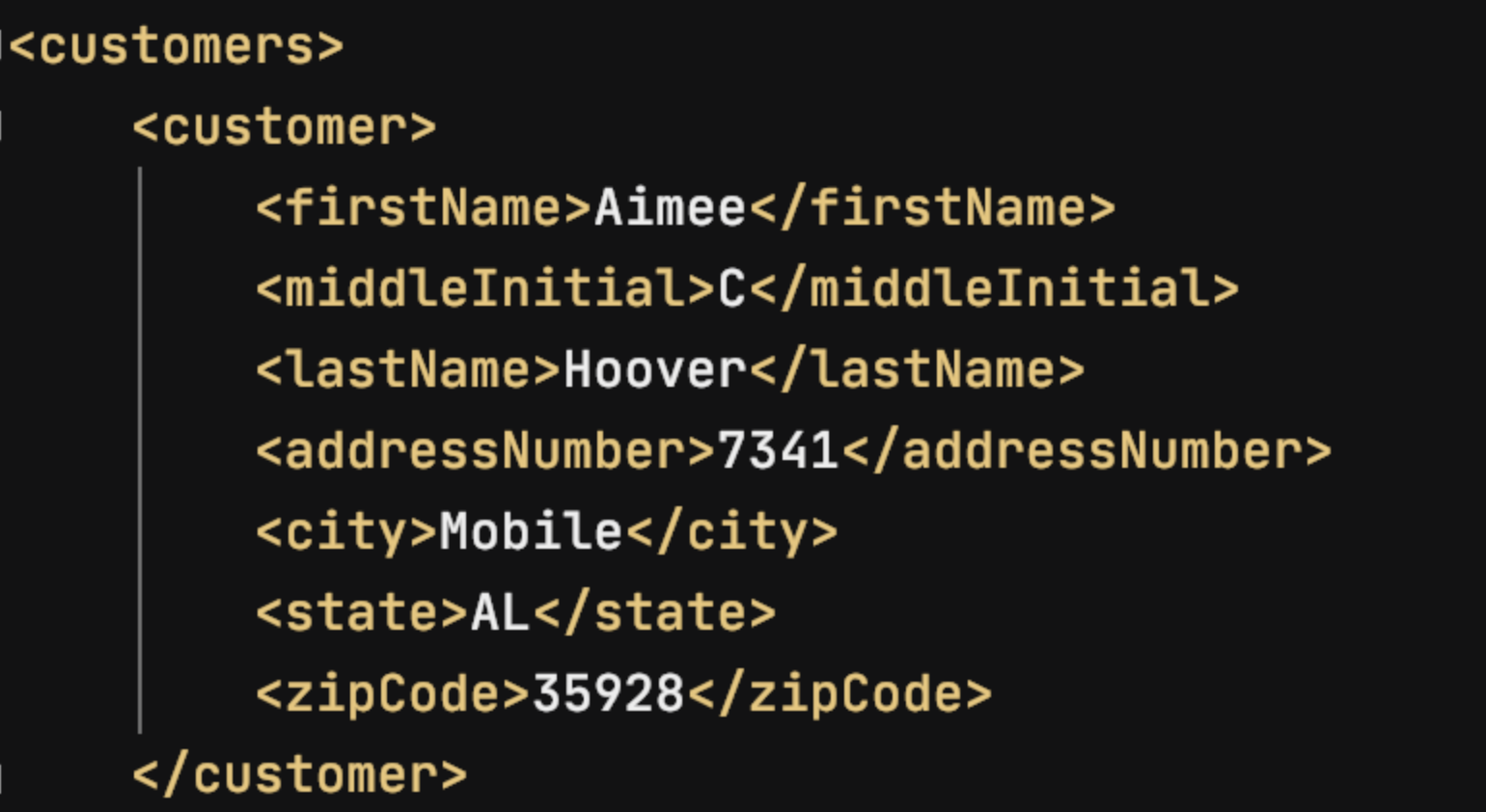
데이터베이스 기반 ItemWriter
파일기반 쓰기 작업은 트랜잭션과 분리되었지만 데이터베이스는 트랜잭션의 일부분으로 포함할 수 있음.
JdbcBatchItemWriter
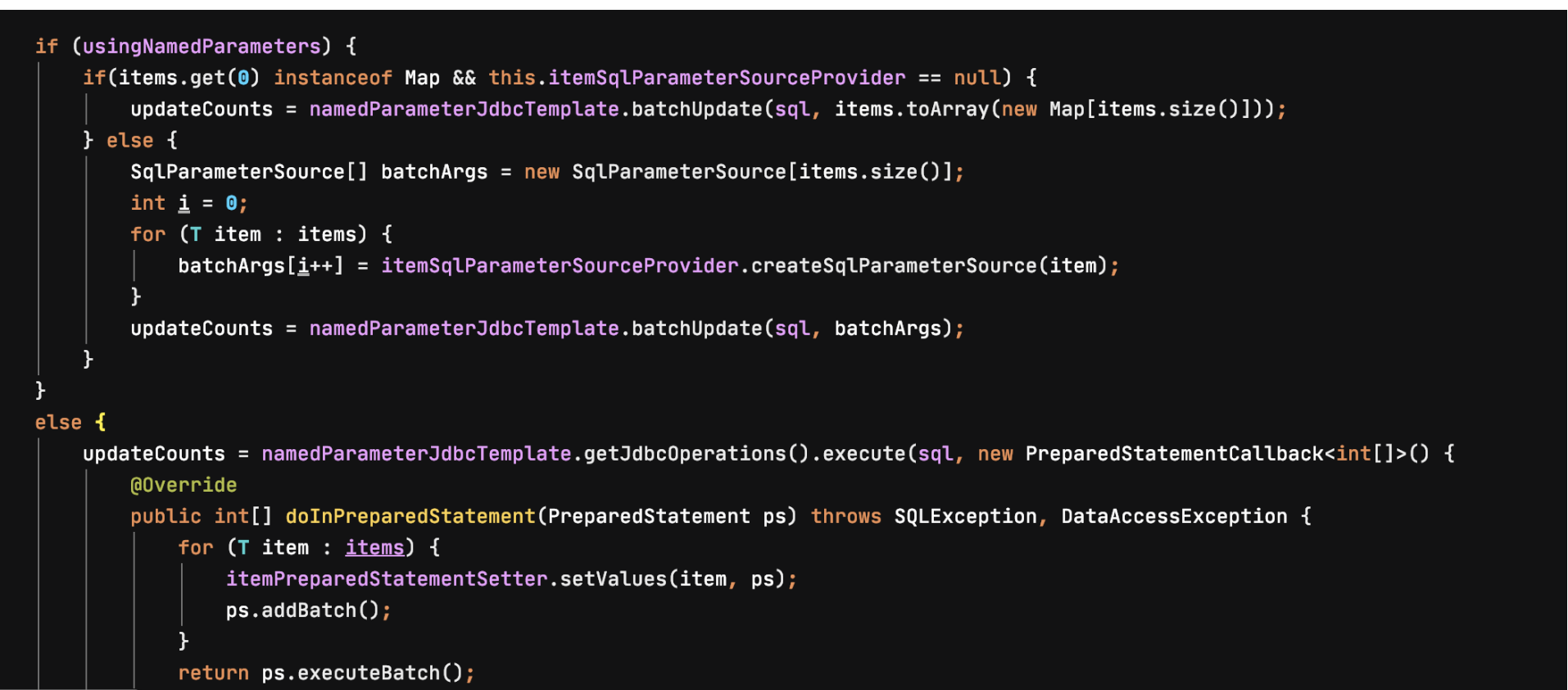
NamedParameterJdbcTemplate에 batchUpdate나 execute 를 위임하는 래퍼
public JdbcBatchItemWriter<Customer> jdbcBatchItemWriter(DataSource dataSource) {
return new JdbcBatchItemWriterBuilder<Customer>()
.dataSource(dataSource)
// .sql("INSERT INTO CUSTOMER (first_name, middle_initial, last_name) VALUES (?, ?, ?)") // preparedStatement 를 사용함으로써 성능을 크게 올릴 수 있음
.sql("INSERT INTO CUSTOMER (first_name, middle_initial, last_name) VALUES (:firstName, :middleInitial, :lastName)") // namedParameter 사용을 더 권장
.beanMapped() // Customer 의 프로퍼티 네임으로 매핑됨
// .itemPreparedStatementSetter(new CustomerItemPreparedStatementSetter())
.build();
}
static class CustomerItemPreparedStatementSetter implements ItemPreparedStatementSetter<Customer> {
@Override
public void setValues(Customer item, PreparedStatement ps) throws SQLException {
ps.setString(1, item.getFirstName());
ps.setString(2, item.getMiddleInitial());
ps.setString(3, item.getLastName());
}
}HibernateItemWriter
@Bean
public HibernateItemWriter<CustomerEntity> hibernateItemWriter(EntityManagerFactory entityManagerFactory) {
return new HibernateItemWriterBuilder<CustomerEntity>()
.sessionFactory(entityManagerFactory.unwrap(SessionFactory.class))
.build();
}JpaItemWriter
public JpaItemWriter<CustomerEntity> jpaItemWriter(EntityManagerFactory entityManagerFactory) {
JpaItemWriter<CustomerEntity> jpaItemWriter = new JpaItemWriter<>();
jpaItemWriter.setEntityManagerFactory(entityManagerFactory);
return jpaItemWriter;
}'Reading Record > 스프링 배치 완벽 가이드' 카테고리의 다른 글
| 8장 ItemProcessor (0) | 2021.12.06 |
|---|---|
| 7장 ItemReader: JDBC 부터 (0) | 2021.11.29 |
| 7장 ItemReader: Json 까지 (0) | 2021.11.22 |
| 6장 잡 실행하기 (0) | 2021.11.15 |
| 5장 JobRepository와 메타데이터 (0) | 2021.10.30 |

